
Photo by
ThisisEngineering RAEng
on
Unsplash
The Slowdown in Scientific Productivity#
Scientific progress is notoriously hard to measure. At first glance, we seem to be making great strides:
- The annual growth rate of scientists is now over 4 percent, compared to a world annual population increase of about 1.1 percent.
- Science (loosely defined as citations, scientific papers, books, datasets, etc) is increasing in quantity by about 8-9 percent a year.
However, when we look at the effort required to make those discoveries as well as their downstream impacts, we see a different story:
- On average, the size of research teams nearly quadrupled over the 20th century. For many research questions, it requires far more skills, expensive equipment, and a large team to make progress today.
- The average age of scientists who received a Nobel Prize was 37 years old in the early 1900’s. Today, it is 47 years old. A possible explanation is that it takes more time to make ground-breaking scientific progress.
- American life expectancy was rising at about 3.8 years per decade before 1950, but slowed to roughly 1.8 years per decade after 1950. Is the rate of medical innovation slowing down?
- U. S. economic growth slowed by more than half from 3.2 percent per year during 1970-2006 to only 1.4 percent during 2006-16. Perhaps scientific productivity is a huge downstream factor here.
Why We Should Care#
All innovation and technology we enjoy today is the result of science. Vaccines, cars, planes, a cure for cancer, you name it. Before the Wright brothers, flying “like a bird” was thought to be impossible. Now, we complain about the TSA making us remove our shoes.
It’s entirely possible that speeding up the rate of scientific progress can make the difference between intergalactic space travel being possible in our lifetime or not.
Scientific Growing Pains#
In the beginning, science was more local. Most fields of science didn’t exist yet. Of those that did, they didn’t have many sub-fields. Scientific communities were smaller. If you wanted to be a scientist in a particular domain, you moved to wherever those scientists were, and you apprenticed under them. When you had questions, you asked.
Today, science is happening at a massive scale, which has had a few negative effects:
-
Information overload. The sheer volume of discoveries is unbelievable: about 2.5 million scientific papers are published each year. The more information we have, the more important it is to structure and index it properly. If you ask most scientists how they keep up with all the new ideas nowadays, they'll say that there are too many.
Ian Goodfellow (an esteemed deep learning researcher) said this about keeping up:
Not very long ago I followed almost everything in deep learning, especially while I was writing the textbook. Today that does not seem feasible, and I really only follow topics that are clearly relevant to my own research.
-
Knowledge fragmentation. Specialization is a natural consequence of completing a PhD. Ideas build on each other. Domains split into subdomains, which split into sub-subdomains, and so on. As a result, even scientists in the same general field can have trouble accessing and understanding each other's work.
-
Simplicity is not incentivized. More papers to review means journals and conferences take shortcuts when deciding how remarkable a discovery is. Making your discovery seem more innovative and complex can help you get published in the more prestigious journals and conferences.
A metaphor from Chris Olah, a research scientist at Google Brain, on conducting science:
Achieving a research-level understanding of most topics is like climbing a mountain. Aspiring researchers must struggle to understand vast bodies of work that came before them, to learn techniques, and to gain intuition. Upon reaching the top, the new researcher begins doing novel work, throwing new stones onto the top of the mountain and making it a little taller for whoever comes next.
Today, the mountains are
- huge (information overload),
- copious (knowledge fragmentation), and
- treacherous (lack of simplicity).
In general, the journey to become (and stay) a scientist requires sifting through and ingesting far more information. There are several tools, like Google and Wikipedia, that help alleviate this problem but don’t solve it completely.
The Inadequacy of Our Current Tools#
So wait, what's wrong with just Googling what you want to find?
A few things:
- Knowledge duplication is everywhere. Google can serve millions of results - most of it with overlapping content. This creates noise and makes searching for very specific ideas difficult.
- The relationship between ideas is the most important. If you want to know how x and y are related, you have to Google "how x and y are related" and hope it exists. It's insufficient to simply Google "x" followed by "y".
- You have to know what you’re looking for (to some degree). We often either don’t know exactly what we want to find or have ideas that are hard to phrase as a search. Google doesn't support this well.
- Google is optimized for a single errand — not an entire learning journey. Google can bring you to ideas, but not between them.
And what about Wikipedia?
Wikipedia does help with 2, 3, and 4, but misses two knowledge graph properties: granularity and normalization.
Granularity: Wikipedia is biased towards articles on various subjects - a consistent level of detail. If you just want a summary, it’s too verbose: you won’t read most of the page. If you want details, it’s too high level: you’ll have to go elsewhere for a more tailored source. With knowledge graphs, you can continuously zoom in and out depending on what level of abstraction you need.
Normalization: Part of Wikipedia’s verbosity is due to information duplication. If you go to the Wikipedia page on pigs, it tells you that pigs can “acquire human influenza”. You can also find the same information on the Wikipedia page about the flu: “Influenza may also affect other animals, including pigs...” In one-off use cases, like a quick Google search, this isn’t too big of a deal. However, if you’re traversing from node to node (or page to page), this redundancy becomes a bigger factor and degrades the user experience. By “normalizing” the content (i.e. removing redundancy), that problem is removed.
An Ideal Solution#
Let’s do some brainstorming on qualities this tool would ideally preserve:
- Ideas are atomic. Since they’ll be building blocks for bigger ideas, they need to be comprehensive, but terse.
- Ideas are referenced multiple times, but live in one place. From a computational point of view, duplication causes anomalies and headaches.
- Ideas can have multiple views. Although each view of an idea is an idea itself, they will all be manifestations of the same core idea. It’s also possible that a view can have multiple core ideas.
- There is no siloing. If two ideas are related, they will be connected.
- Similar ideas are “close” to each other (i.e. low degree of separation).
- Searching can be done via traditional means (e.g. keywords and categories), but also through serendipitous traversal.
Storing knowledge this way can result in a whole range of applications. A few examples:
- Finding ideas becomes more natural: You can just start with the idea you think is most similar, and iterate towards what you’re looking for.
- Digesting ideas becomes more practical: Just look at what ideas it’s composed of and which ideas it has as neighbors.
- If ideas seem terse, it’s likely that different views of it exist and are immediately accessible.
- Automatic generation of books, blog posts, etc, specifically tailored to the reader. How? Just enumerate a specific path through the graph, and you have an outline for the piece!
To provide a rough sketch of what I have in mind, here's how a portion of such a graph representing programming languages could look like:
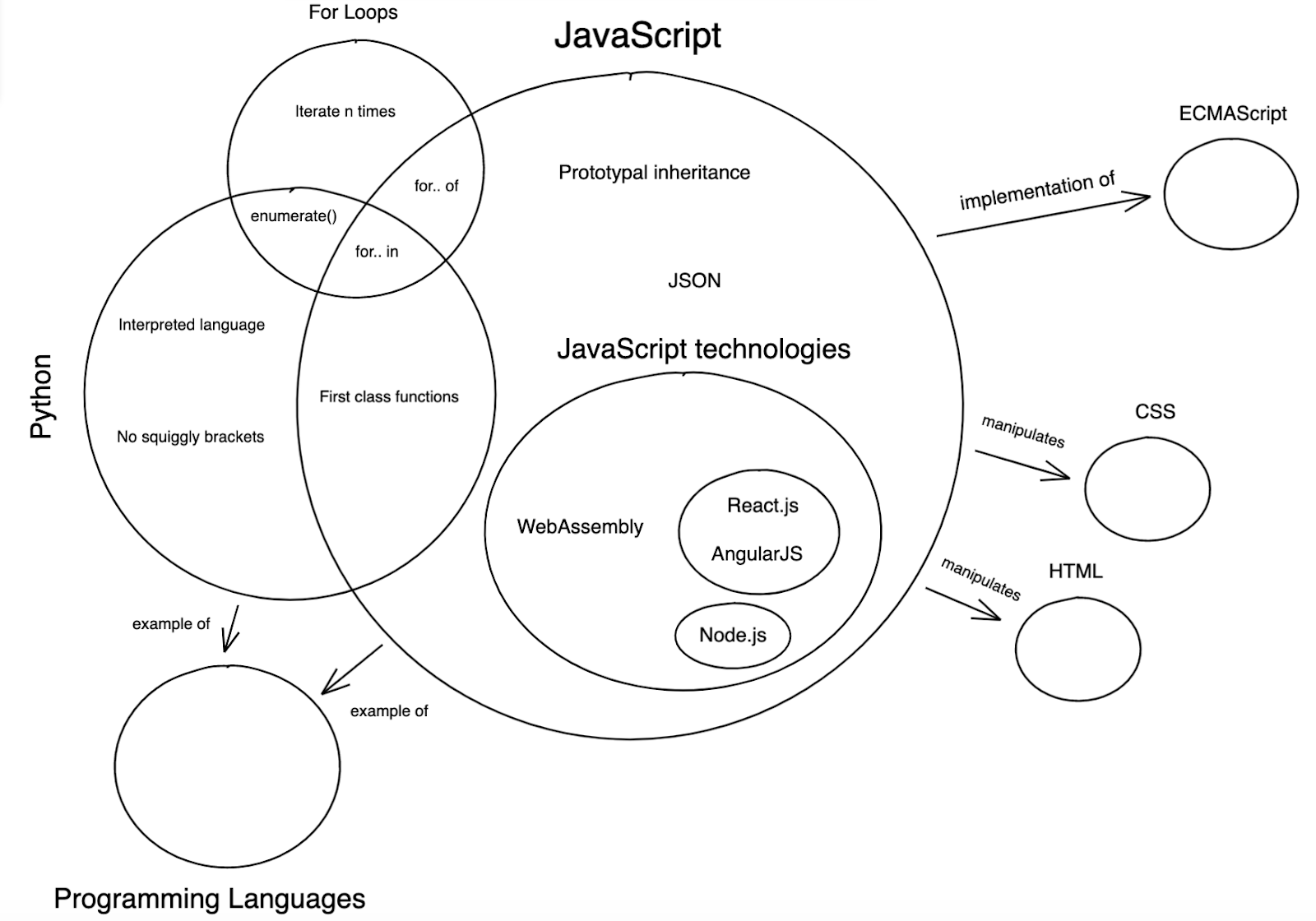
Imagine if every expert built their own knowledge graph with the properties specified beforehand.
Because of the “single source of truth” property for every idea, combining them with other knowledge graphs becomes more straightforward. Duplicate ideas are merged, new ideas are coalesced, and contradictory ideas are distilled into commonalities connected by separate branches.
Eventually, we will have one massive, centralized knowledge graph that the entire world can access.
Thank you to the Compound Writing members who reviewed this post: Joel Christiansen, Stew Fortier, Ross Gordon, Gian Segato, Nick deWilde, Tom White, and Michael Shafer.